3.3.5 Character Encoding
Table of Contents
1 ASCII and Unicode
Learn It
- Every time a character is typed on a keyboard a code number is transmitted to the computer.
- The code numbers are stored in binary on computers as
Character SetscalledASCII. - The table below shows a version of ASCII that uses 7 bits to code
each character. The biggest number that can be held in 7-bits is
1111111in binary (127 in decimal). Therefore 128 different characters can be represented in the ASCII character set (Using codes 0 to 127). More than enough to cover all of the characters on a standard English-Language keyboard. - Click here for the full ASCII table.
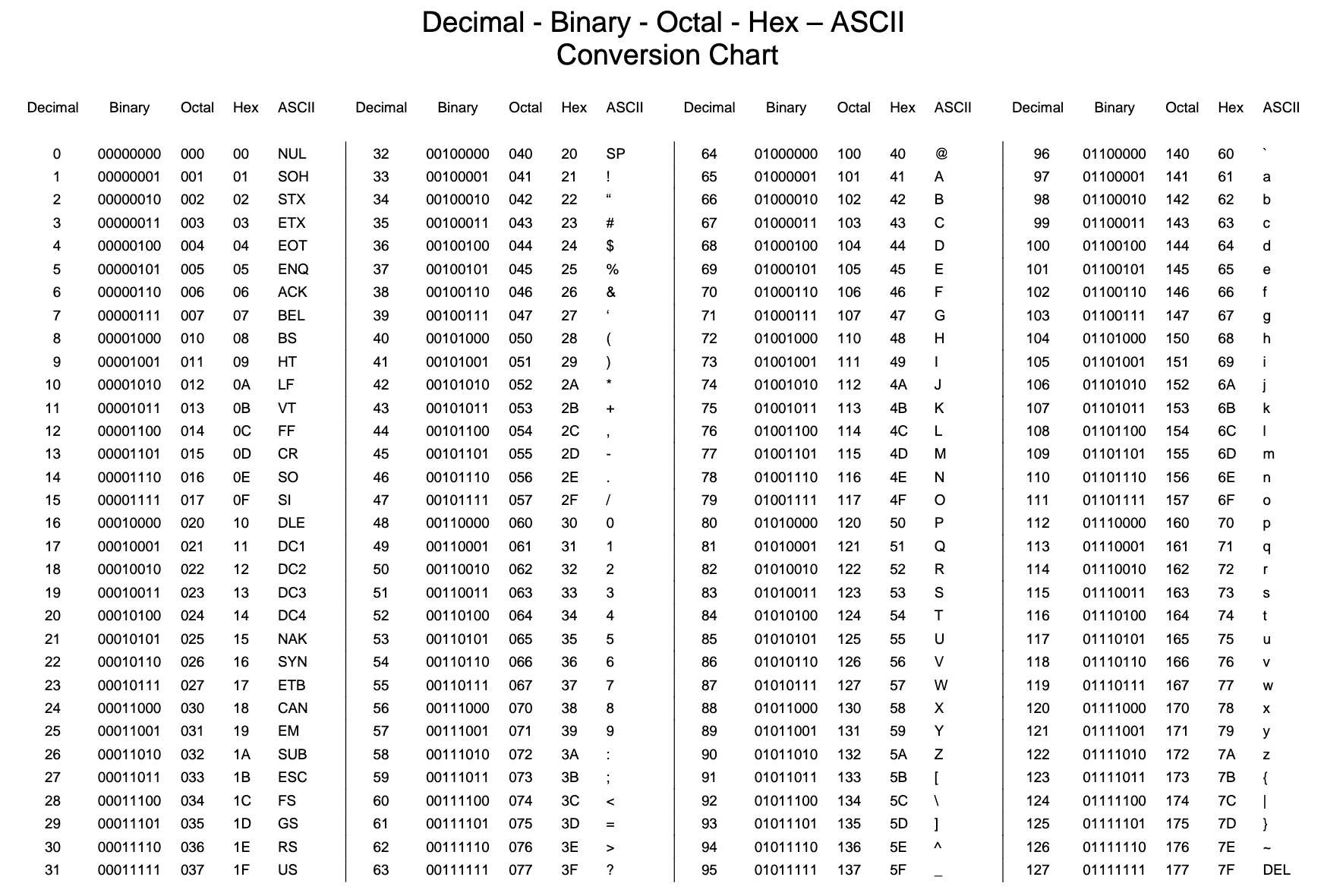
"Originally based on the English alphabet, ASCII encodes 128 specified characters into 7-bit binary integers as shown by the ASCII chart above.The characters encoded are numbers 0 to 9, lowercase letters a to z, uppercase letters A to Z, basic punctuation symbols, control codes that originated with Teletype machines, and a space. For example, lowercase j would become binary 1101010 and decimal 106. ASCII includes definitions for 128 characters: 33 are non-printing control characters (many now obsolete)that affect how text and space are processed and 95 printable characters, including the space." – from wikipedia
- The ASCII has been used for a long time. But it has some serious shortcomings:
- It only uses English alphabets.
- It is limited to 7-bits, so it can only represent 128 distinct characters.
- It is not usable for non-latin languages, such as Chinese.
- Character form of a decimal digit In ASCII, the number character is not the same as the actual number value. For example, the ASCII value 011 0100 will print the character '4', the binary value is actually equal to the decimal number 52. Therefore ASCII cannot be used for arithmetic.
2 Using the ASCII Table in Programming
Learn It
- The character codes are grouped and run in sequence; i.e. If
Ais65thenCmust be67. - The pattern applies to other groupings such as digits and lowercase
letters, so you can say that since
7is55,9must be57. Also,7<9anda>A. - Notice that the ASCII code value for
5(0011 0101) is different from the pure binary value for 5 (0000 0101). That's why you cannot calculate with numbers which are input as strings. - Another example, the ASCII value
011 0100will print the character4, the binary value is actually equal to the decimal number52.
3 Character Sets
Learn It
Extended ASCII
- The basic ASCII codes use 7-bits for each character (As shown in the table above). This gives a total of 128 (27) possible unique symbols.
- The
Extended ASCIIcharacter set uses 8-bits, which gives an additional 128 characters (i.e. 256 in total). - The extra characters represent characters from foreign languages and special symbols such as Ö € or →.
Unicode
Unicode(Unique, Universal, and Uniform character enCoding) is the new standard for representing characters ofall the languages of the World. This has been introduced to address the shortcomings of ASCII.- The latest version of Unicode contains a repertoire of more than 120,000 characters covering 129 modern and historic scripts, as well as multiple symbol sets.
- ASCII character encoding is a subset of Unicode.
- Unicode can be implemented by different character encodings. The
Unicode standard defines
UTF-8,UTF-16andUTF-32. - So, these use between
8 and 32 bitsper character and has the advantage that it represents many more unique characters than ASCII because of the larger number of bits available to store a character code. - It uses the same codes as ASCII up to 127.
UTF-8, the dominant encoding on the World Wide Web (used in over 92% of websites), uses one byte for the first 128 code points, and up to 4 bytes for other characters. The first 128 Unicode code points are the ASCII characters, which means that any ASCII text is also a UTF-8 text.UTF-16, uses16 bitsto represent each character. This means that it is capable of representing65,536 different characters.UTF-32, uses32 bitsto represent each character, meaning it can represent a character set of4,294,967,296 possible characters, enough for all known languages.- Its major advantage is that it provides a unique standard for all the World's writing systems. It allows for multilingual text in any language.
- Unicode advantages over ASCII
- Can have representation of a greater range of characters.
- More languages or all (modern) languages can be represented (in one character set).
- Improved portability of documents in Unicode as each character has a unique representation in Unicode.
Badge It
Silver: Translate the following ASCII code message into English. The decimal codes of the characters have been used. So 65 would be uppercase A and 97 would be lowercase a:
84 104 101 32 65 83 67 73 73 32 99 111 100 101 32 114 101 112 114 101 115 101 110 116 115 32 99 104 97 114 97 99 116 101 114 115 46
Badge It
Gold: Answer the following question:
1. Using extended 8-bit ASCII, how many bytes would be required to store the phrase 'Computer Science'?
Badge It
- Platinum: Create an algorithm asking a user to input a sentence and then print the codes (in decimal) for each of the characters or symbols with each one printed on a new line. Code and test the algorithm in Python. Extend this further by creating a function for this and to also accept a decimal value which then returns the ASCII character.